Architecture
This page gives you an overview of the InfiniStream architecture.
InfiniStream makes running NATS/JetStream a breeze by replacing the installation and maintenance of NATS cluster with a stateless binary that communicates with object storage like S3 and the cloud metadata store. InfiniStream agents are NATS protocol compatible, speak the same protocol (infact the agent is derived from the NATS server), but unlike the cluster, any agent can act as the leader, create streams and consumers and write and read sequences. No agent is special when it comes to interacting with the clients and scaling it based on CPU or Network metrics is simple. It’s as easy as running a web server to say the least.
InfiniStream does not support all the message delivery models that NATS supports. It only supports the JetStream streaming model and that too pull only.
What makes it so simple to install, configure, run and balance, without worrying about routers or leaf nodes or space management?
- Storage is separated from compute
- Data is separated from metadata
- Data plane resides with customer, control plane is in the cloud
- JetStream only, pull only
Separating Storage from Compute
Section titled “Separating Storage from Compute”Separating storage from compute is a familiar technique for scaling modern data processing systems. It allows you to scale your compute clusters up or down, in or out in response to load while leveraging low-cost storage managed by someone else, such as Amazon S3. It allows any compute node to process data from any stream in storage.
Separating storage and compute allows operators to scale up or down the number of InfiniStream Agents to respond to changes in load without rebalancing data. It also enables faster recovery from failures because any request can be retried on another Agent immediately. We also eliminate hotspots, where some NATS servers have dramatically higher load than others due to uneven amounts of data in a stream.
These hard tricky problems have been delegated to hyper-scale cloud provider object storage services, where tremendous effort and billions of dollars have been invested to provide previously unseen levels of durability, availability, and operational excellence.
Separating Data from Metadata
Section titled “Separating Data from Metadata”Another key notion of InfiniStream’s design is the separation of data from metadata. This is also becoming a more common technique, where one might store store primary data in Object storage and metadata in Relational database.
InfiniStream uses this technique to offload metadata management from our customers’ operations teams to ours. We store the metadata for every group in our cloud metadata store designed to only solve this specific problem, operated 24x7 by us. This separation also provides useful security guarantees as we cannot read the data in your streams, even if our cloud was compromised.
Separating Data Plane from Control Plane
Section titled “Separating Data Plane from Control Plane”At a high level, the data plane of a InfiniStream virtual group is a pool of Agents connected to our cloud. Any Agent in any pool can serve any produce or consume request for streams in that virtual cluster. The control plane runs in our cloud, where we decide which Agents will be tasked with compacting your data files for optimal performance, which Agents will participate in the distributed, zone-aware object storage cache, and which Agents will scan your object storage bucket for files which are past retention and can be deleted.
Our control plane enables us to deliver on our promise of a NATS/JetStream compatible streaming system that is as easy to operate as a webserver by offloading the hard problems of quorum and coordination onto our fully-managed control plane, while at the same time achieving a much lower TCO with the object storage-backed data plane running on the Agents.
JetStream only, pull only
Section titled “JetStream only, pull only”NATS does many things. InfiniStream does JetStream only and only pull via the PullSubscribe()/Fetch() call. This simplifies a lot of things, scales a lot better, puts less load on the agents and makes seperating the data plane and the control plane possible.
Cost and performance considerations
Section titled “Cost and performance considerations”Bolting a message stora on top of S3 will end up with either extremely high latency, or a huge S3 API operations bill. If every message is stored in a S3 object, the PUT’s will be plenty and the GET calls will become very costly. Bunching messages for a long time and pushing it will be cost effective, but the latency will be something that is not expected of todays systems.
InfiniStream Agents make a write a few objects per second, but each object contains sequences from multiple streams. In the background the pool of Agents compacts those small objects into larger ones to make reprocessing streams cost effective and provide good throughput. By combining these two properties one can get good response with good cost savings.
Our Architecture
Section titled “Our Architecture”As you can see in the architecture diagram, the agents run in the customers VPC and the customer data never leaves their VPC. Only metadata about the streams and sequences in the group are sent to the InfiniStream cloud. Applications connect to the agent pool using the standard NATS clients.
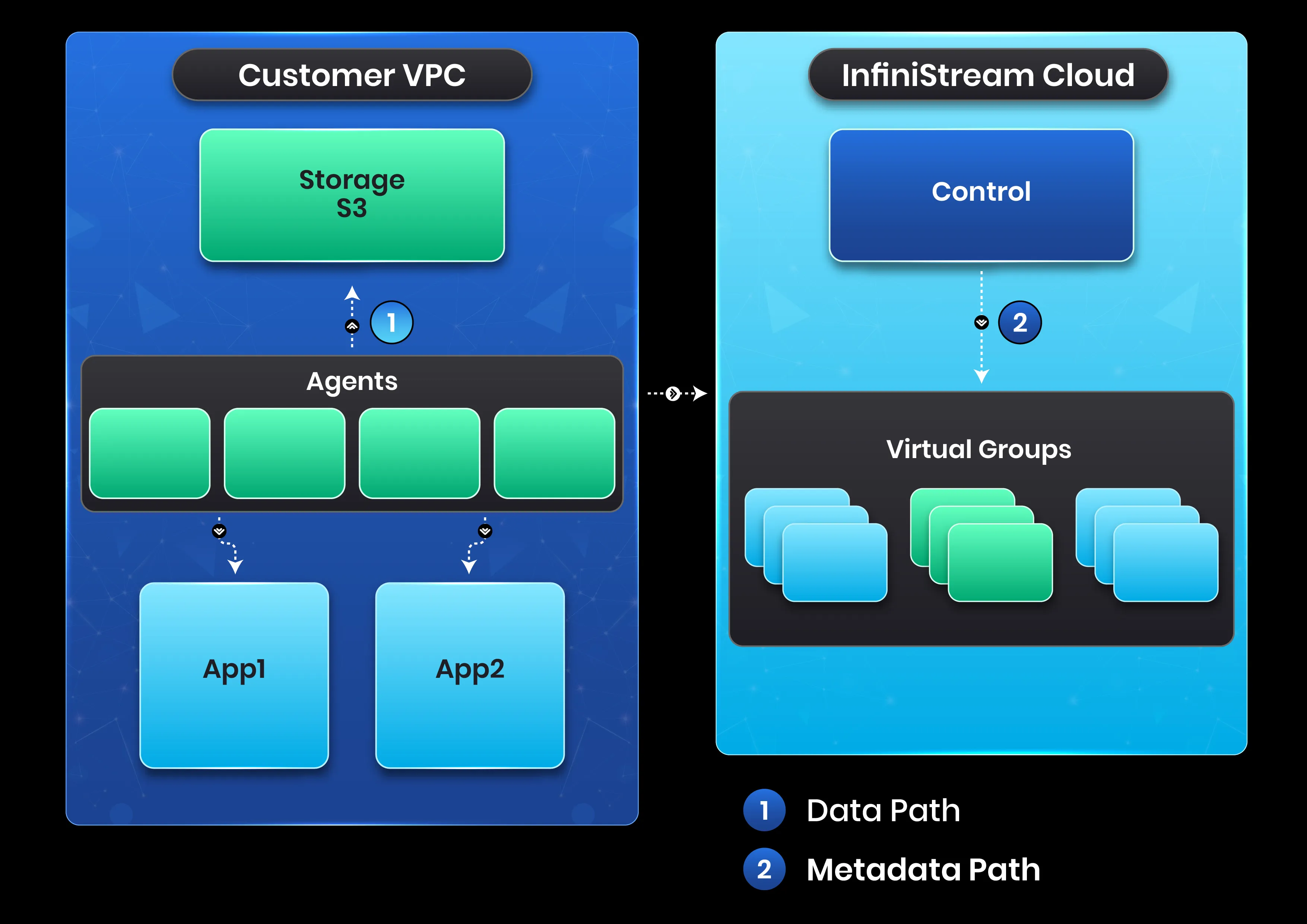
Virtual Group
Section titled “Virtual Group”A Virtual Group is a logical metadata store for InfiniStream. Each customer can create multiple isolated Virtual Groups for separating teams or departments. JetStream API operations within a Virtual Group are atomic, including generating sequences and deletion. Each Virtual Group is a replicated state machine which stores the mapping between files in object storage and sequences in each stream.
Every Virtual Group metadata operation is transacted to our strongly-consistent consensus based distributed key-value storage system before acknowledged back to the Agent, which then acknowledges the request from your client application.
Within a Virtual Group, the Agents can optionally be allocated to each serve a specific role. This feature is only possible in InfiniStream due to its decoupled architecture and cloud-native design.
Cloud Layer
Section titled “Cloud Layer”Our Cloud Services layer manages the lifecycle of each replica of your Virtual Groups. Each Virtual Group has multiple consistent replicas for high availability and is backed by our distributed key-value storage system. Replacement replicas of your Virtual Group are created when existing replicas fail by joining a new node and bringing it up to sync. The system continues to operate even when the new node is catching up, thereby minimizing interruption to your operations.
The Cloud Services layer also powers our administrative control panel and the observability system for your Virtual Group metrics. This Cloud Services layer is an isolated deployment per region, as are the Virtual Groups underneath it