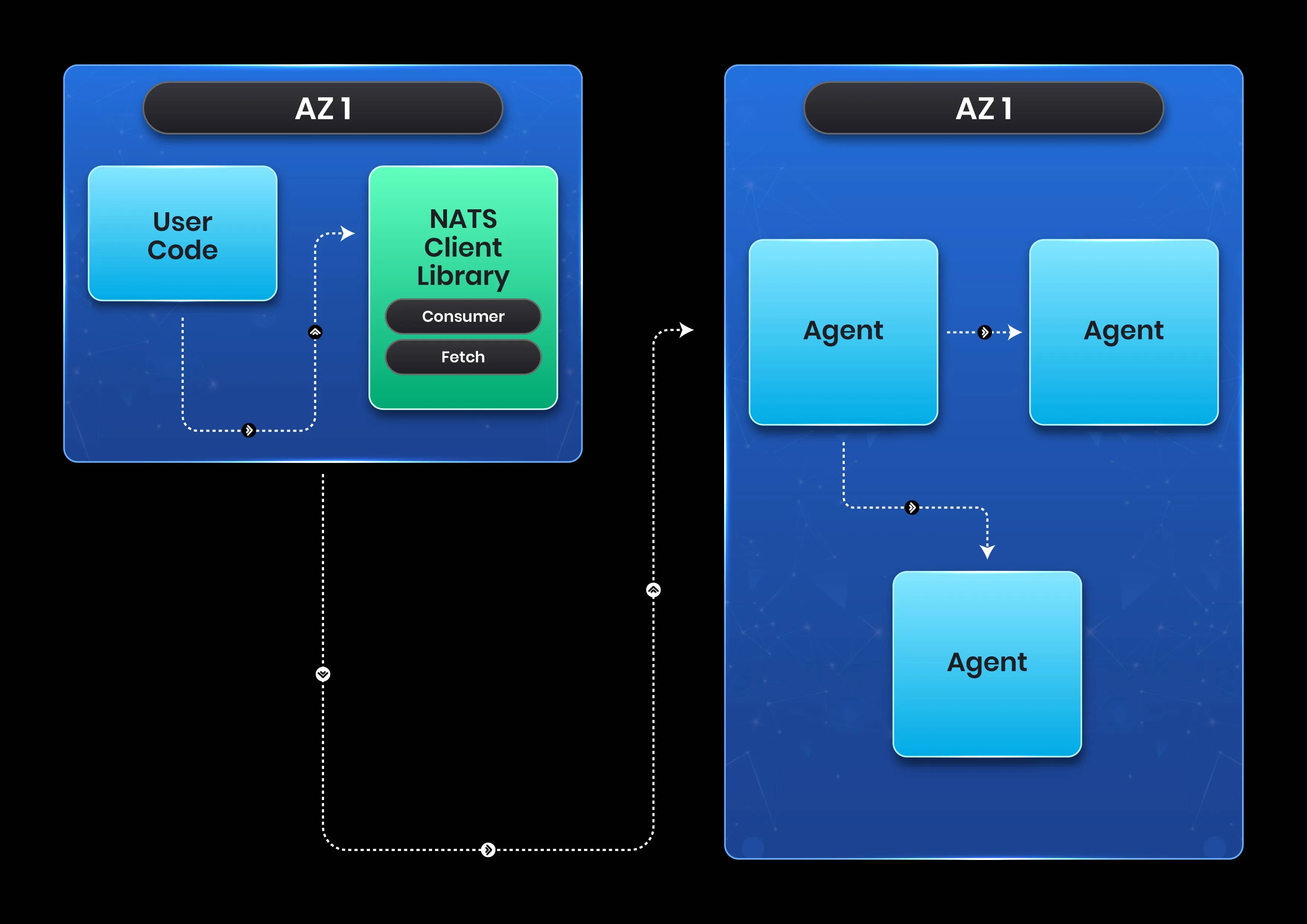
Request Lifecycle
Explains the flow of a JetStream Publish() and a Fetch() request from client to InfiniStream Agent to InfiniStream Cloud and back
Publish
Section titled “Publish”Our client publishes messages by connecting to a leader node in its availability zone. All clients should connect to same agent in same availability zone for better compaction.
Publish requests arrive on an arbitrary Agent and are batched together with other Publish requests from other clients happening concurrently. Once the Agent’s batching interval has elapsed, or the Active Buffer is full, sequence numbers are generated on a per strem basis and the Active Buffer is serialized to InfiniStream’s file format and passed to the Flush Queue to be written to object storage.
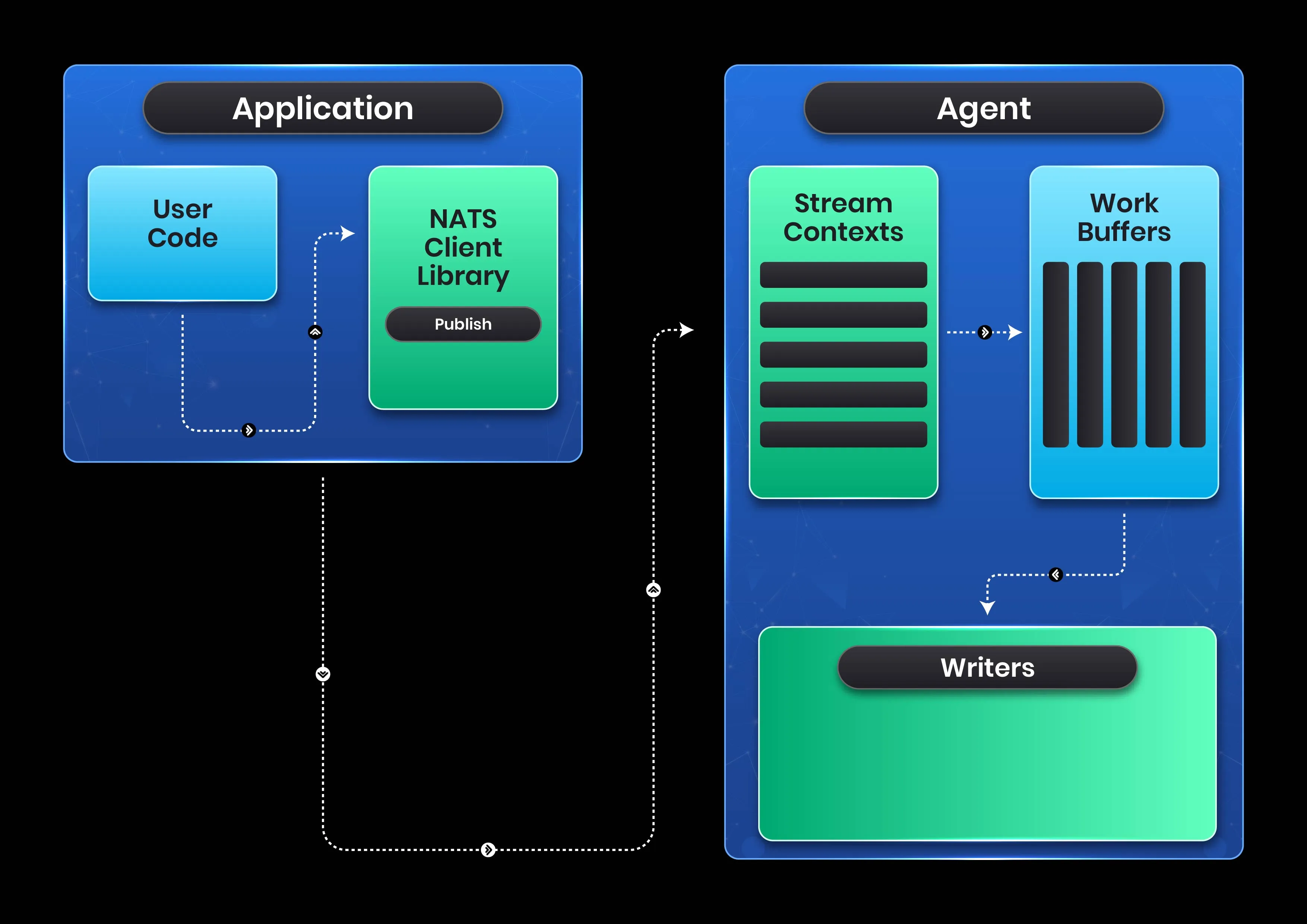
Once the file is flushed to object storage, the metadata for that file is sent to the InfiniStream Cloud and an object id is obtained for each buffer flushed. The object storage is named with object id and all the sequences are recorded in the virtual group for the different streams.
Let’s assume for simplicity that your client is only reading a single stream. Your request will be processed by some Agent, and that Agent will send a command to the InfiniStream Cloud that eventually will be processed by your group. This command instructs your virtual group to return the set of object id’s that contain data starting with the sequence number in your Fetch request at that moment in time.