Writing data
How writes in InfiniStream work and how we persist data.
Introduction
Section titled “Introduction”Writes in InfiniStream is designed to be networking efficient and cost efficient especially when one operates many streams.
Equally, InfiniStream is easy to configure and operate. It’s possible because it directly uses object storage as it’s primary storage.
Keeping costs low by leveraging object storage directly and keeping latency low as well is something that is pretty challenging. We try to explain the direction we took to square the above contradiction.
How writes work
Section titled “How writes work”- Any agent can commit a write
- If writes happen from clients in the same availability zone, there’s no networking or storage cost
- Data is written to object storage, transaction committed to InfiniStream control plane and then acknowledged
Coalescing writes
Section titled “Coalescing writes”InfiniStream agents buffer writes to Streams from Publish() calls from multiple NATS connections and then write these sequences as a batch to object storage. By default, the agents buffer for 250ms or 4Mb of coalesced data, whichever happens first.
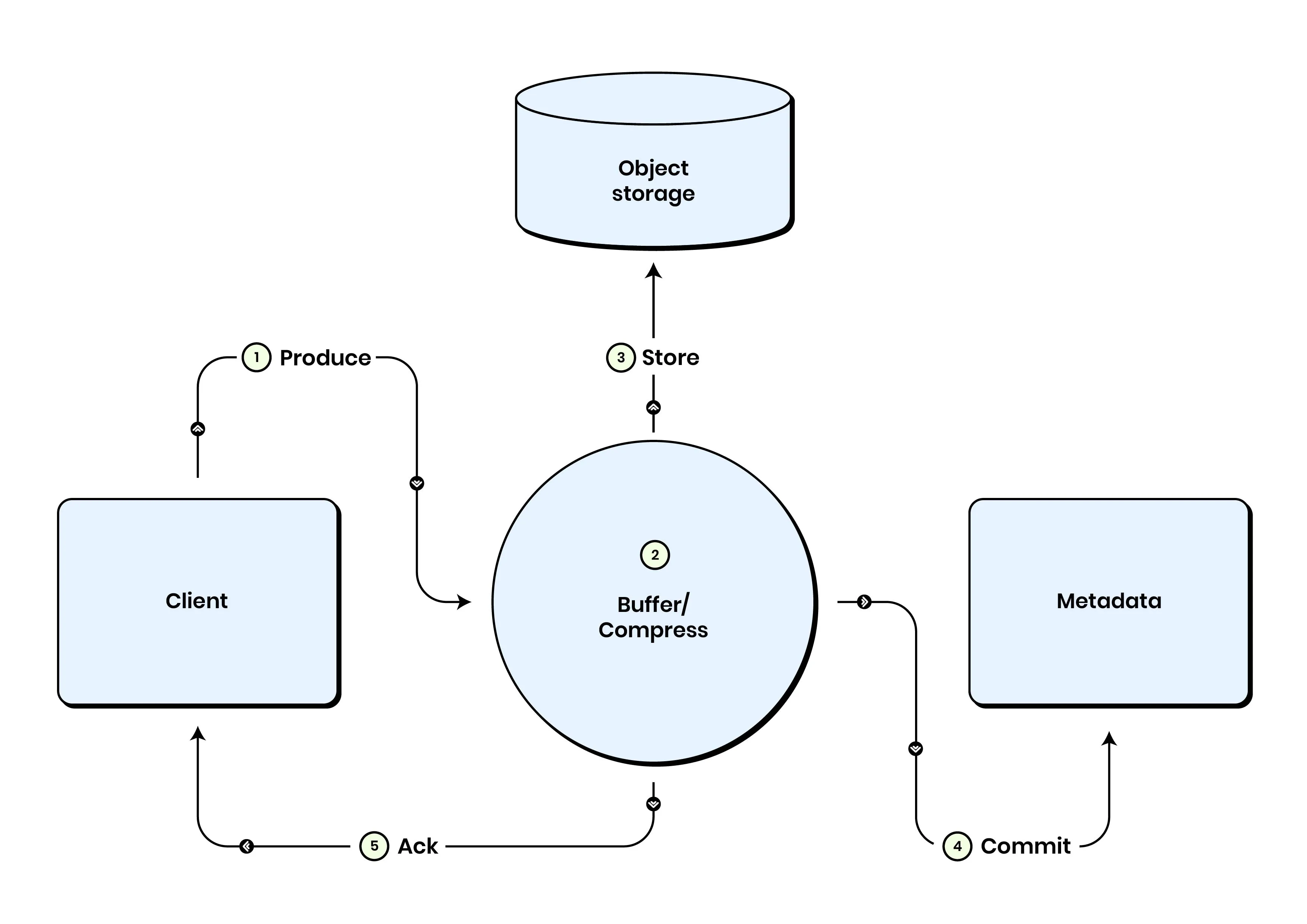
After the file is written to object storage, the Agent commits the file metadata to the InfiniStream control plane, and then acknowledges all of the Publish() requests in the batch back to the clients. InfiniStream never acknowledges writes until data is durably persisted in object storage and committed to the metadata store.
Unlike JetStream, InfiniStream does not write every sequence to memory (and fsync to disk if sync_interval: always is set)
as that would require writing many small files to object storage or buffering data in-memory for an
unacceptably long period of time. Instead, it merges sequences from multiple streams into one and writes them, thereby
keeping cost and latency low.

By using object store directly, there’s no need to co-ordinate between servers for a corpus which greatly simplifies InfiniStream’s architecture and operations.
- No need to manage space or move streams to other servers (balance)
- InfiniStream agents can be scaled up or down to zero with no data movement
- No loss of acknowledged data even if the agents are lost
File compaction
Section titled “File compaction”InfiniStream agent designated to compact objects can coalsce multiple sequences in stream stream into a single object to speed up access as most of the access patterns are sequential in nature. It also reduces GET’s which is a costed call.
Durability
Section titled “Durability”Publish requests are not acknowledged until the data is persisted in the object store and the metadata is
committed to InfiniStreams’s metadata store. This is similar to JetStreams’s AckAll semantics,
however cloud object storage systems such as Amazon S3 have much better durability guarantees
than what can be accomplished with JetStream.
By eliminating local storage, InfiniStream is able to provide stronger durability
guarantees than what can be achieved using triply replicated SSDs.
Ordering and Idempotency
Section titled “Ordering and Idempotency”InfiniStream maintains the exact same ordering guarantees and idempotency guarantees as JetStream. As with JetStream, messages produced to a specific stream in JetStream are assigned sequence numbers in the order that they are sent, and consumers will read the messages in sequence order.
To maintain ordering within a stream, while still enabling a sequences to be appended to from dozens of different Agents, InfiniStream generates sequence numbers in the control plane in the order it receives requests for the next sequence number for a stream and not when when the data is flushed to object storage. This approach enables the Agents to massively parallelize writes, while still maintaining the same ordering and idempotency guarantees as JetStream.
Notes: 1
Footnotes
Section titled “Footnotes”-
We have followed the same order as WarpStream documentation for easy reading and collation ↩